软件分析期末复习
软件分析概述
静态分析(Static Analysis)和动态测试(Dynamic Testing)的区别是什么?
- 静态分析(Static Analysis)是指在实际运行程序$P$之前,通过分析静态程序$P$本身来推测程序的行为,并判断程序是否满足某些特定的性质(Property)$Q$。
- 动态测试是指通过运行程序$P$,收集程序的运行时信息来观察代码运行状况。
完全性(Soundness)、正确性(Completeness)、假积极(False Positives)和假消极(False Negatives)分别是什么含义?
一个静态分析$S$。我们定义程序P的关于$Q$的真实行为为真相(Truth)。
- 完全性(Soundness):真相一定包含在$S$给出的答案中;
- 正确性(Completeness):$S$给出的答案一定包含在真相中。
记这个静态分析程序给出的答案集合$A$,真相集合为$T$,则完美的静态分析满足:
\[T \subseteq A \wedge A \subseteq T \Leftrightarrow A = T\]其中,$T \subseteq A$体现了完全性,$A \subseteq T$体现了正确性。
- 假积极:记程序$P$的关于性质$Q$的静态分析$S$有假积极(False Positive)问题,当且仅当$S$给出的答案$A$和$P$关于$Q$的真相$T$满足如下关系:
其中,$a$称为一个假积极实例(False Positive Instance),其实是一个消极实例(Negative Instance)。
- 假消极:记程序$P$的关于性质$Q$的静态分析$S$有假消极(False Negative)问题,当且仅当$S$给出的答案$A$和$P$关于$Q$的真相$T$满足如下关系:
其中,$a$称为一个假消极实例(False Negative Instance),其实是一个积极实例(Positive Instance)。
为什么静态分析通常需要尽可能保证完全性?
- Sound 的静态分析可以帮助我们有效的缩小 debug 的范围,我们最多只需要在$A$范围内暴力排查掉所有的假积极实例(False Positive Instance)就可以了,人工排查的代价是可控的。
- Complete 的静态分析做不到这一点,它不能够帮助我们有效缩小 debug 的范围。因为假消极实例(False Negative Instance)$a\notin A$,所以$a$的范围是$P−A$。这里注意的是,虽然假消极的理论范围是$T−A$,但因为我们并不知道$T$是什么,所以只能从$P−A$中排查。而$P−A$往往是比$A$大得多的,因此排查假消极的代价是很大的。
如何理解抽象(Abstraction)和过近似(Over-Approximation)?
- 抽象(Abstraction):当我们考虑程序$P$的性质$Q$时,程序$P$中的各种值,我们或许不一定非得事无巨细。比如说,当我们考虑除零错误(Zero Division Error)的时候,对于某个值,我们只需要判定其是否为$0$即可,至于它具体是多大,我们其实不关心,因为它和我们要研究的性质$Q$没有直接关联。这种将$P$中的值的,和我们需要研究的性质$Q$相关的性质提取出来,从而忽略其他细节的过程,就是一个抽象的过程。
- 过近似(Over-Approximation):软件分析中的转移函数与控制流,针对程序中的语句,对抽象域上的结果提供转换规则,达到soundness的目标。
程序的中间表示
编译器(Compiler)和静态分析器(Static Analyzer)的关系是什么?
静态分析器是现代编译器的一部分。编译器由源代码生成中间表示之后,静态分析器对中间表示进行处理,编译器根据静态分析器的输出做出优化,或者报出错误与警告。
三地址码(3-Address Code, 3AC)是什么,它的常用形式有哪些?
一些常见的三地址码形式如下:
x = y bop z
x = uop y
x = y
goto L
if x goto L
if x rop y goto L
x、y、z是变量的地址,地址可能是- 名字(Name),包括,
- 变量(Variable)
- 标签(Label):用于指示程序位置,方便跳转指令的书写
- 字面常量(Literal Constant),
- 编译器生成的临时量(Compiler-Generated Temporary);
- 名字(Name),包括,
bop是双目操作符(Binary Operator),可以是算数运算符,也可以是逻辑运算符;uop是单目操作符(Unary Operator),可能是取负、按位取反或者类型转换;L是标签(Label),是标记程序位置的助记符,本质上还是地址;rop是关系运算符(Relational Operator),运算结果一般为布尔值。goto是无条件跳转,if... goto是条件跳转。
如何在中间表示(Intermediate Representation, IR)的基础上构建基块(Basic Block, BB)?
基块就是满足如下性质的最长指令序列:
- 程序的控制流只能从首指令进入;
- 程序的控制流只能从尾指令流出。
一个基块的领导者就是这个基块的首指令,整个程序中的领导者有如下3种:
- 整个程序的首指令;
- 跳转指令(包括条件跳转和无条件跳转)的目标指令;
- 跳转指令(包括条件跳转和无条件跳转)紧接着的下一条指令。
从前到后扫一遍,获得所有的Leader。再从前到后扫一遍,按Leader分段即可。
如何在基块的基础上构建控制流图(Control Flow Graph, CFG)?
程序控制流的产生来源于两个地方:
- 天然的顺序执行,这是计算系统天然存在的一种控制流;
- 跳转指令,这是人为设计添加的一种控制流。
扫一遍所有的基块:
- 如果一个基块的末尾是跳转,就从这个基块向跳转目标连一条边;
- 只要一个基块的末尾不是无条件跳转,就从这个基块向下一个基块连一条边。
数据流分析
定义可达性(Reaching Definitions)分析、活跃变量(Live Variables)分析和可用表达式(Avaliable Expressions)分析分别是什么含义?
- 可达性分析:程序中变量$v$的一个定义(Definition)是指一条给$v$赋值的语句。我们称在程序点$p$处的一个定义$d$到达(Reach)了程序点$q$,如果存在一条从$p$到$q$的“路径”(控制流),使得在这条路径上,定义$d$始终未被覆盖(Kill)。称分析每个程序点处能够到达的定义的过程为定义可达性分析(Reaching Definition Analysis)。定义可达性分析可以应用于检测程序中可能存在的未被定义的变量。
- 活跃变量分析:在程序点$p$处
- 某个变量$v$的变量值(Variable Value)可能在之后的某条控制流中被用到,我们就称变量$v$是程序点$p$处的活变量(Live Variable)
- 否则,我们就称变量$v$为程序点$p$处的死变量(Dead Variable)。
分析在各个程序点处所有的变量是死是活的分析,称为活跃变量分析(Live Variable Analysis)。通过活跃变量分析,可以知道某个变量当前所储存的值在之后有没有可能被用到。
- 可用表达式:我们称一个表达式(Expression)
x op y在程序点$p$处是可用的(Avaliable),如果:- 所有的从程序入口到程序点$p$的路径都必须经过
x op y表达式的评估(Evaluation),并且 - 在最后一次
x op y的评估之后,没有$x$或者$y$的重定义(Redefinition)。
对于程序中每个程序点处的可用表达式的分析,我们称之为可用表达式分析(Avaliable Expression Analysis)。有了可用表达式分析,在计算表达式的时候可以直接复用之前的结果。
- 所有的从程序入口到程序点$p$的路径都必须经过
上述三种数据流分析(Data Flow Analysis)有哪些不同点?又有什么相似的地方?
- 数据抽象
- 可达性分析:对于每个程序点,分析能够到达该点的定义的集合。
- 活跃变量分析:对于每个程序点,分析该点所有活变量的集合。
- 可用表达式分析:对于每个程序点,分析该点所有可用表达式的集合
- 约束分析
-
可达性分析:使用过近似(可能性分析),正向分析,转移方程:
\[OUT[B] = gen_B \cup (IN[B] - kill_B)\]控制流约束:
\[IN[B] = \bigcup_{P\in pre(B)}OUT[P]\]初始化的时候,所有基块$B$的$OUT[B]$都被初始化为空集。
-
活跃变量分析:使用过近似(可能性分析),反向分析,转移方程:
\[IN[B] = use_B \cup (OUT[B] - def_B)\]控制流约束:
\[OUT[B] = \bigcup_{S\in suc(B)}IN[S]\]初始化的时候,所有基块$B$的$IN[B]$都被初始化为空集。
-
可用表达式分析:使用欠近似(必然性分析),正向分析,转移方程:
\[OUT[B] = gen_B \cup (IN[B] - kill_B)\]其中$gen_B$为基块$B$中的所有的表达式的集合,$kill_B$为程序中所有的其中变量被$B$重定义的表达式的集合。控制流约束:
\[IN[B] = \bigcap_{P\in pre(B) OUT[P]}\]初始化的时候,除了程序入口之外的其他基块$B$的$OUT[B]$都应该被初始化为全集。
-
总结:
| 定义可达性分析 | 活跃变量分析 | 可用表达式分析 | |
|---|---|---|---|
| 定义域 | 定义集的幂集 | 变量集的幂集 | 表达式集的幂集 |
| 方向 | 正向分析 | 逆向分析 | 正向分析 |
| 估计 | 过近似 | 过近似 | 欠近似 |
| 边界 | $OUT[ENTRY]=\emptyset$ | $IN[EXIT]=\emptyset$ | $OUT[ENTRY]=\emptyset$ |
| 初始化 | $OUT[B] = \emptyset$ | $IN[B]=\emptyset$ | $OUT[B] = U$ |
| 状态转移 | $OUT[B] = gen_B \cup (IN[B] - kill_B)$ | $IN[B] = use_B \cup (OUT[B] - def_B)$ | $OUT[B] = gen_B \cup (IN[B] - kill_B)$ |
| 交汇 | $IN[B] = \bigcup\limits_{P \in pre(B)} OUT[P]$ | $OUT[B] = \bigcup\limits_{S \in suc(B)} IN[S]$ | $IN[B] = \bigcap\limits_{P \in pre(B)} OUT[P]$ |
如何理解数据流分析的迭代算法?数据流分析的迭代算法为什么最后能够终止?
在迭代算法中,每轮迭代都逐一分析所有基块,尝试对基块的分析结果进行更新。若在某轮迭代中,所有基块的分析结果都不变,那么算法终止。
以定义可达性分析为例,$OUT[B]$不会收缩,只会变大或者不变。程序中所有定义构成的全集$D$是有限的,基块集合$B$也是有限的,在最慢的情况下,每次迭代只能使得一个基块$B$的$OUT$集合增加一个元素,此时需要的迭代次数是
\[|D|\times |B|\]这是有限的。
如何从函数的角度来看待数据流分析的迭代算法?
- 给定一个具有$k$个结点的程序流程图CFG,对于CFG中的每个结点$n$,迭代算法的每一次迭代都会更新$OUT[n]$;
-
设数据流分析的定义域为 $V$,我们可以定义一个$k$元组(k-tuple)来表示每次迭代后的分析值:
\[(OUT[n_1],OUT[n_2],\dots,OUT[n_k]) \in V \times V \times\dots\times V=V^k\] - 每次迭代可以视为将$V^k$中的某个值映射为$V^k$中的另一个值,通过状态转移方程和控制流约束式,这个过程可以抽象为一个函数$F_{V^k \to V^k}$;
- 然后这个算法会输出一系列的k元组,直到某两个连续输出的k元组完全相同的时候算法终止。
| 初始化 | $(\perp, \perp, \dots, \perp) = X_0$ |
|---|---|
| 第$1$次迭代 | $(v_1^1, v_2^1, \dots, v_k^1) = X_1 = F(X_0)$ |
| 第$2$次迭代 | $(v_1^2, v_2^2, \dots, v_k^2) = X_2 = F(X_1)$ |
| …… | …… |
| 第$i$次迭代 | $(v_1^i, v_2^i, \dots, v_k^i) = X_i = F(X_{i-1})$ |
| 第$i+1$次迭代 | $(v_1^{i+1}, v_2^{i+1}, \dots, v_k^{i+1}) = X_{i+1} = F(X_i) = X_i$ |
其中,$v_i^j$表示第$i$个结点第$j$次迭代后的数据流值。
格和全格的定义是什么?
- 格:考虑偏序集 $(P,\preceq)$,如果$\forall a,b\in P$,$a\vee b$和$a\wedge b$都存在,则我们称$(P,\preceq)$为格(Lattice)。简单理解,格是每对元素都存在最小上界和最大下界的偏序集。
- $(\mathbb{Z},\leq)$是格,其中$\vee=\max,\wedge=\min$;
- $(2^S,\subseteq)$ 也是格,其中$\vee=\cup,\wedge=\cap$。
- 全格:考虑偏序集$(P,\preceq)$,如果$\forall S \subseteq P$,$\vee S$和$\wedge S$都存在,则我们称$(P,\preceq)$为全格(Complete Lattice)。简单理解,全格的所有子集都有最小上界和最大下界。
- 由于$(\mathbb{Z},\leq)$,子集$\mathbb{Z}^+$没有最小上界,因此它不是全格;
- 与之不同的, $(2^S,\subseteq)$就是一个全格。 每一个全格$(P,\preceq)$都有一个序最大(Greatest)的元素$⊤=\vee P$称作顶部(Top),和一个序最小(Least)的元素$⊥=\wedge P$称作底部(Bottom)。
每一个有限格(Finite Lattice)$(P,\preceq)$($P$是有限集)都是一个全格。
如何理解不动点定理?
- 单调性:我们称一个函数$f_{L\to L}$($L$是格)是单调的(Monotonic),具有单调性(Monotonicity),如果$\forall x,y\in L,x\preceq y\Rightarrow f(x) \preceq f(y)$。
- 不动点:我们称$x$是一个函数$f$的不动点(Fixed Point),如果$f(x)=x$。
-
不动点定理:考虑一个全格$(L,\preceq)$。我们定义一个格的高度$h$为从底部到顶部的最长路径。如果$f_{L\to L}$是单调的且$L$是有限集,那么序最小的不动点(Least Fixed Point)可以通过如下的迭代序列找到:
\[f(⊥),f(f(⊥)),...,f^{h+1}(⊥)\]序最大的不动点(Greatest Fixed Point)可以通过如下的迭代序列找到:
\[f(⊤),f(f(⊤)),...,f^{h+1}(⊤)\]其中,$h$是$L$的高度。
怎样使用格来总结可能性分析与必然性分析?
我们将采用过近似策略,输出所有可能为真的信息的数据流分析称为可能性分析(May Analysis),将采用欠近似策略,输出信息必然为真的数据流分析称为必然性分析(Must Analysis)。
-
可能性分析:以Reaching Definitions为例,从某个程序点的视角来看,初始化的时候是$⊥$,即没有任何定义可以到达此处,然后我们一次次迭代,每次迭代向前走最安全的一步,发现越来越多的定义能够到达此处,直到算法在一个最小的不动点处停了下来。
首先,初始化的状态是不安全的,因为没有任何定义可达显然是一个最不正确的结论。其次,$⊤$状态是最安全的,所有的定义都“可能”到达此处,但这是一个没有用的平凡的结论,因为它并不能帮到我们什么,且我们啥也不干都知道这个结论。
我们假设这个程序点处真实可达的定义集合为 Truth ,那么 包含 Truth 且越接近 Truth 的答案才是最有价值的。因此,在包含 Truth 的前提下最小的不动点是最好的。
至于最小的不动点为什么会包含 Truth ,这是由我们设计的转移方程和控制流约束函数所决定的,需要具体的问题具体分析。言下之意,如果我们设计的状态转移方程和控制流约束函数不合理,最小不动点可能会是不安全的,也就是算法可能会出错。
-
必然性分析:我们以典型的必然性分析——Avaliable Expressions为例。从某个程序点的视角来看,我们初始化的时候是 $⊤$ ,即所有的表达式都是可用的,然后我们一次次迭代,每次迭代向前走最安全的一步,发现越来越少的表达式是可用的,直到算法在一个最大的不动点处停了下来。
首先,初始化的状态是不安全的,因为所有的表达式都可用显然是一个最不正确的结论(如果我们用这个结论来作表达式优化,是最会导致程序错误的)。其次,$⊥$ 状态是最安全的,所有的表达式都不可用(也就是我们并不能优化,啥也不用干就行),但这是一个没有用的结论,因为它并不能帮助我们优化表达式,减少计算次数。
我们假设这个程序点处真实可用的表达式集合为 Truth ,那么包含于 Truth (注意,可能性分析里面是包含,必然性分析里面是包含于)且越接近 Truth 的答案才是最有价值的。因为包含于 Truth 说明用这个结果做优化一定不会错,越接近 Truth 那么我能够优化掉的表达式才越多,优化效果越好。因此,在包含于 Truth 的前提下最大的不动点是最好的。
至于最大的不动点为什么会包含于 Truth ,这是由我们设计的状态转移方程和控制流约束函数所决定的,需要具体问题具体分析。言下之意,如果我们设计的状态转移方程和控制流约束函数不合理,最大不动点可能会是不安全的,也就是算法可能会出错。
迭代算法提供的解决方案与 MOP 相比而言精确度如何?
MOP解决方案:数据流分析的全路交汇(Meet-Over-All-Paths)的解决方案通过如下步骤计算某个程序点$(s_i,s_{i+1})$处的数据流值,记为$MOP[s_i]$:
- 考虑从程序入口到$s_i$处的路径$P$的状态转移方程$F_P$,所有路径的集合记为$Paths(ENTRY,s_i)$;
-
使用联合或者交汇操作来求这些值的最小上界或者最大下界。
形式化表示为:
\[MOP[s_i]=\bigvee_{\forall P\in Paths(ENTRY,s_i)}F_P(OUT[ENTRY])\]或
\[MOP[s_i]=\bigwedge_{\forall P\in Paths(ENTRY,s_i)}F_P(OUT[ENTRY])\]
这显然是一种非常暴力的算法。
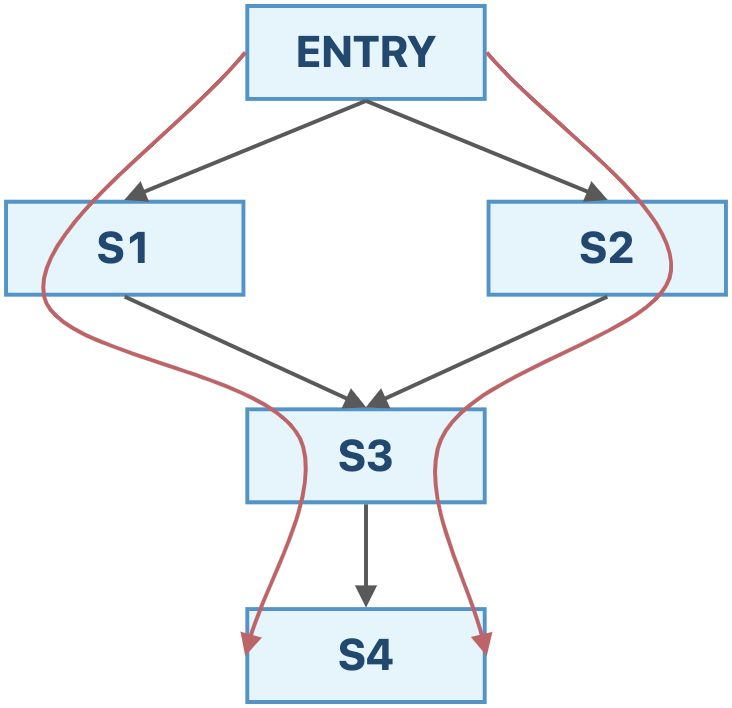
我们通过一个例子来比较一下这两个算法。如果采用迭代算法,我们最终得到的结果为:
\[IN[s_4]=f_{s_3}(f_{s_1}(OUT[ENTRY])\vee f_{s_2}(OUT[ENTRY]))\]如果采用MOP算法,我们最终得到的结果为:
\[IN[s_4]=f_{s_3}(f_{s_1}(OUT[ENTRY]))\vee f_{s_3}(f_{s_2}(OUT[ENTRY]))\]从这个例子中,我们可以发现,迭代算法求的是$F(x\vee y)$ ,而MOP算法求的是$F(x)\vee F(y)$(如果是交汇操作也是类似的)。 由于$F(x)\vee F(y) \preceq F(x∨y)$,迭代算法的精度不如MOP。
我们称定义在格$(L,\preceq)$上的函数$f(x)$满足分配律(Distributive),如果$f(x\vee y)=f(x)\vee f(y)$,$f(x\wedge y)=f(x)\wedge f(y)$。当$F(x)$满足分配律的时候,迭代算法的精度和MOP是一样的。并且,上面提到的三种数据流分析的状态转移方程都是满足分配律的。也就是说,在这些情景下,迭代算法可以达到MOP算法的精度,但是其实现要比MOP简单得多。
什么是常量传播(Constant Propagation)分析?
常量传播(Constant Propagation)问题:考虑程序点$p$处的变量$x$,求解$x$在$p$点处是否保证(Guarantee)是一个常量。 如果我们知道了某些程序点处的某些变量一定是一个常量的话,我们就可以直接优化,将这个变量视为常量,从而减少内存的消耗(可以在编译的时候就完成一部分计算,并且有些常量并不需要分配储存它的内存空间)。
我们可以用一个有序对$(x,v)$的集合表示每个程序点处的抽象程序状态,其中$x$是变量名,$v$是变量的常数值,$v$的取值可能有某个常数,$UNDEF$(Undefined,未定义的)或$NAC$(Not A Constant,不是常量)。
状态转移:考虑语句s: x = ...,定义其状态转移方程为
定义$gen_s$如下:
s: x = c; //c is a constant,则$gen_s={(x,c)}$ ;s: x = y; ,则$gen_s={(x,val(y))}$;s: x = y op z; ,则$gen_s={(x,f(y,z))}$,其中,
常量传播的转移方程是不满足分配律的。
控制流约束:
- $(x,v) \wedge (x,NAC)=(x,NAC)$,变量和任意常量交汇还是变量,因为我们需要保证是一个常量,采用的是必然性分析的策略;
- $(x,UNDEF) \wedge (x,v)=(x,v)$,未初始化的变量并不是我们这个问题的关注点(言下之意出了Undefined的错误,锅由Reaching Definitions背),我们当它不存在即可。
- $(x,v_1)∧(x,v_2)=\begin{cases}(x,v_1), &if v_1=v_2 \ (x,NAC),&otherwise\end{cases}$,两个不同的值汇聚到某一点,说明这个变量不是常量,否则,在这个程序点处,我们可以将其视为常量。
数据流分析的工作表算法(Worklist Algorithm)是什么?
工作表算法是对迭代算法的优化,用一个集合储存下一次遍历会发生变化的基块,这样,已经达到不动点的基块就可以不用重复遍历了。 工作表算法本质上是图的广度优先遍历算法的变体,只是加入了一些剪枝的逻辑,每一轮只遍历可能会发生变化的结点,不发生变化的结点提前从遍历逻辑中去除。
过程间分析
如何通过类层级结构分析(Class Hierarchy Analysis, CHA)来构建调用图(Call Graph)?
-
调用图:调用图是程序中各过程(Procedure)之间调用关系的一种表示,考虑程序中的所有调用点(Call Site,调用表达式所在的语句),所有的从调用点到“目标方法(Target Method)——即被调用者(Callee)”的边组成的集合为调用图(Call Graph)。记程序中所有调用点的集合为$V_1$,所有的方法的集合为$V_2$,调用图$G$满足$G\subseteq V_1\times V_2$。
- 类层级结构分析:通过查找类的层级结构来解析目标方法的过程,称之为类层级结构分析(Class Hierarchy Analysis,CHA)。
- 虚调用的方法派发算法,就是从接受对象所在的类开始,按照从子类向到基类的顺序查找,直到找到一个方法名和描述符都相同的非抽象方法为止。

- CHA的调用解析算法处理虚调用的方式是暴力的枚举,将变量声明类型及其子类中所有和调用点处签名匹配的方法都视为可能的目标方法。
 此算法中$c$的子类包括$c$的直接子类和间接子类。
此算法中$c$的子类包括$c$的直接子类和间接子类。
- 虚调用的方法派发算法,就是从接受对象所在的类开始,按照从子类向到基类的顺序查找,直到找到一个方法名和描述符都相同的非抽象方法为止。
- 通过CHA构建整个程序调用图的基本过程为:
- 从入口方法开始(通常为
main方法); - 对于每个可达的方法$m$,通过CHA解析$m$中的每个调用点$cs$的目标方法,即$Resolve(cs)$;
- 重复上述过程,直到没有发现新的方法为止。
- 从入口方法开始(通常为
如何理解过程间控制流图(Interprocedural Control-Flow Graph, ICFG)的概念?
定义一个程序的过程间控制流图(Interprocedural Control Flow Graph,ICFG)由两个部分组成:
- 程序中所有方法的控制流图,其中的边称为CFG边(CFG Edge);
- 两种额外的边:
- 调用边(Call Edge):从调用点(Call Site)到调用点对应的被调用者(Callee)的入口结点(Entry Node)的边;
- 返回边(Return Edge):从被调用者的出口结点(Exit Node)到返回点(Return Site, 控制流中紧接着调用点的语句)的边。
即ICFG = CFG + call & return edges。
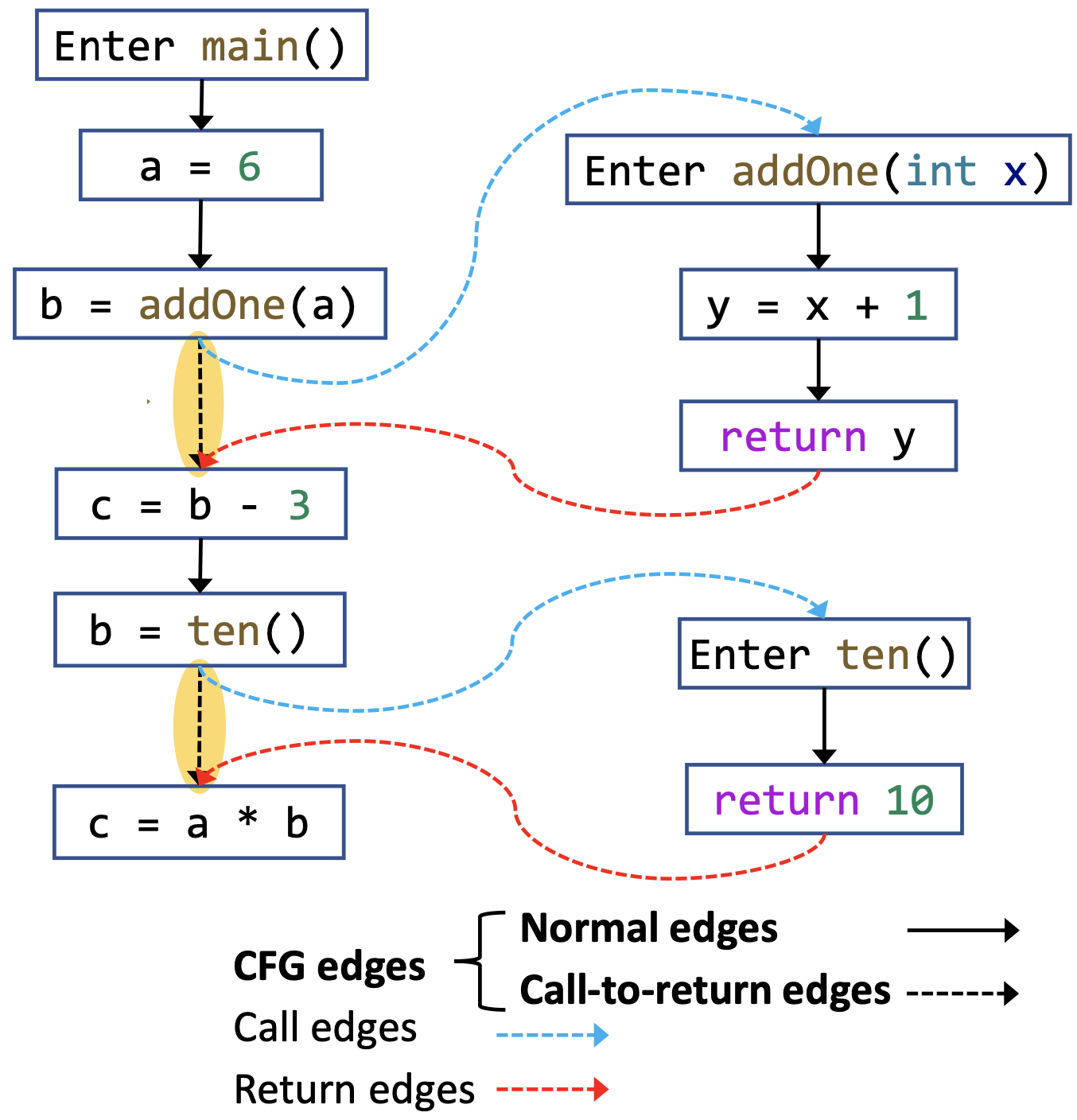
CFG边中从调用点到对应返回点的边称为调用-返回边(Call-to-return edges),除此之外的边称为普通边(Normal Edges)。即CFG Edges = Call-to-return Edges + Normal Edges。调用-返回边相当于为子过程不需要用到的外部状态提供了一条传播的捷径。
如何理解过程间数据流分析(Interprocedural Data-Flow Analysis, IDFA)的概念?
我们将基于CFG分析单个方法内部的数据流分析称为过程内数据流分析(Intraprocedural Data-Flow Analysis),将基于ICFG分析整个程序的数据流分析称为过程间数据流分析(Interprocedural Data-Flow Analysis)。
定义数据流沿着ICFG中的边转移的过程为边转移(Edge Transfer),分为四种:
- 普通边转移(Normal Edge Transfer):数据流沿着某个方法的CFG中的边的转移函数;
- 调用-返回边转移(Call-Return Edge Transfer):数据流从调用点沿着调用-返回边到返回点的转移函数;
- 调用边转移(Call Edge Transfer):数据流从调用点(见定义5.3)沿着调用边转移到被调用者的入口结点的转移函数;
- 返回边转移(Return Edge Transfer):数据流从被调用者的出口结点沿着返回边转移到返回点(见定义5.8)的转移函数。
称CFG中结点所对应的状态转移方程为结点转移(Node Transfer), 包括:
- 调用结点转移(Call Node Transfer):调用点对应的结点的状态转移方程;
- 其他结点转移(Other Node Transfer):调用点以外的其他结点的状态转移方程。
如何进行过程间常量传播(Interprocedural Constant Propagation)分析?
- 结点转移:
- 调用结点转移:恒等函数(Identity Function,即直接将输入当输出返回的函数);
- 调用点左值变量留给调用-返回边处理;
- 其他结点转移:和过程内的常量传播一致;
- 调用结点转移:恒等函数(Identity Function,即直接将输入当输出返回的函数);
- 边转移:
- 普通边:恒等函数
- 调用-返回边:消除调用点的左值变量(Left-hand-side Variable, LHS Variable)的值,传播其他本地变量的值;
- 调用边:传递参数值;
- 返回边:传递返回值。
指针分析
什么是指针分析(Pointer Analysis)?
我们将分析一个指针可能指向的内存区域(Memory Location),以程序(Program)为输入,以程序中的指向关系(Point-to Relation)为输出的分析称作指针分析(Pointer Analysis)。
如何理解指针分析的关键因素(Key Factors)?
| 因素 | 问题 | 选择 |
|---|---|---|
| 堆抽象(Heap Abstraction) | 如何对堆区内存建模? | 分配点(Allocation-site) 无储存(Storeless) |
| 上下文敏感性(Context Sensitivity) | 如何对调用语境建模? | 上下文敏感(Context-sensitive) 上下文不敏感(Context-insensitive) |
| 流敏感性(Flow Sensitivity) | 如何对控制流建模? | 流敏感(Flow-sensitive) 流不敏感(Flow-insensitive) |
| 分析范围(Analysis Scope) | 程序的哪个部分应该被分析? | 全程序(Whole-program) 需求驱动(Demand-driven) |
堆抽象:
堆抽象(Heap Abstraction)是指,为了保证静态分析能够正常终止,将动态分配的(Dynamically Allocated),无界的具体对象(Unbounded Concrete Objects)建模成有限/有界的抽象对象(Finite/Bounded Abstract Objects)的过程。
将同一分配点(Allocation Site ,通常是一条new语句)处分配内存而产生的所有具体对象抽象成一个抽象的对象,称这种堆抽象的方式为分配点抽象(Allocation-Site Abstraction)。一个静态的程序总是有限的,因此程序中的分配点也是有限的,所以我们抽象出来的抽象对象的个数也一定是有限的了。
例:在选择分配点抽象的情况下,尽管new了3个A,但是抽象成同一个对象。
for (i = 0; i < 3; i++) {
a = new A();
......
}
上下文敏感性:
称一个静态分析是上下文敏感的(Context-Sensitive, C.S.),如果它区分一个方法的不同调用语境(Calling Context);称一个静态分析是上下文不敏感的(Context-Insensitive, C.I.),如果它将一个方法所有的调用语境汇合到一起分析。在上下文敏感的分析中,对于每一个调用的上下文都会单独分析,因此,一个方法可能在不同的上下文中被分析很多次。
流敏感性:
称一个静态分析是流敏感的(Flow-sensitive),如果它尊重语句的执行顺序;称一个静态分析是流不敏感的(Flow-insensitive),如果它忽略控制流顺序,将程序视为一个无序语句的集合来对待。
分析范围:
称为程序中所有的指针计算指向信息的指针分析为全程序分析(Whole-program Analysis);称只计算会影响特定兴趣点(Specific Sites of Interest)的指针的指向信息的指针分析为需求驱动分析(Demand-driven Analysis)。
我们在指针分析的过程中具体都分析些什么?
只聚焦于指针影响型语句(Pointer-affecting Statements):
| 语句类型 | 示例 |
|---|---|
| New(创建新对象) | x = new T() |
| Assign(赋值语句) | x = y |
| Store(字段存储语句) | x.f = y |
| Load(字段载入语句) | y = x.f |
| Call(方法调用语句) | r = x.k(a, ...) |
这些语句会影响下列类型的指针:
- 本地变量(Local Variable),形如
x; - 静态域(Static Field),形如
C.f;- 有时候也称为全局变量(Global Variable)
- 实例域/实例字段(Instance Field),形如
x.f;- 在指针分析的时候建模成
x指向的对象的域f;
- 在指针分析的时候建模成
- 数组元素(Array Element),形如
array[i];- 在指针分析时,我们会忽略数组下标,建模成
array指向的一个对象,这个对象只有一个字段arr,可能指向数组中存放的任意值。
- 在指针分析时,我们会忽略数组下标,建模成
对于数组的简化,下面是一个例子:
- 实际代码
array = new String[10]; array[0] = "x"; array[1] = "y"; s = array[0]; - 指针分析视角的代码
array = new String[]; array.arr = "x"; array.arr = "y"; s = array.arr;
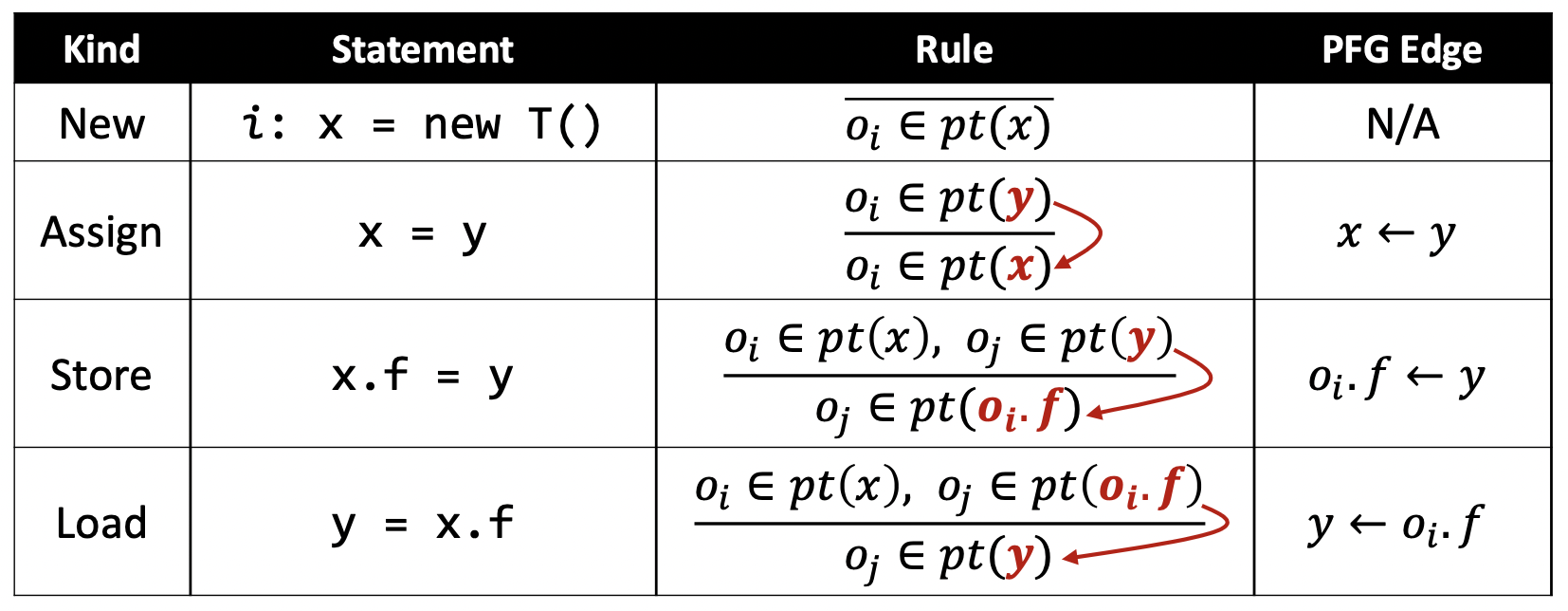
指针分析的规则(Pointer Analysis Rules)是什么?
记程序的指针集为$Pointer$,对象集合为$O$,其幂集记为$P(O)$,定义指向关系(Points-to Relation)是从$Pointer$到$P(O)$映射,用$pt$表示,满足
\[pt\subseteq Pointer \times P(O)\]于是,我们可以用$pt(p)$来表示指针$p$的指向集合(Points-to Set)。
我们用推导式的方式来描述各种语句在指针分析中的规则。考虑命题$P_1, P_2, \dots, P_m$和命题$Q_1, Q_2, \dots, Q_n$,定义推导式(Comprehension)形式如下:
\[\frac{P_1, P_2, \dots, P_m}{Q_1, Q_2, \dots, Q_n}\]其含义是,若$P_1, P_2, \dots, P_m$为真,则$Q_1, Q_2, \dots, Q_n$为真。 其中,$P_i$称为前提(Premises),$Q_j$称为结论(Conclusion)。若$m=0$,则称结论无条件(Unconditional)成立。
| 类型 | 语句 | 规则 | 图示 |
|---|---|---|---|
| 创建 | i: x = new T() |
$\overline{o_i \in pt(x)}$ | 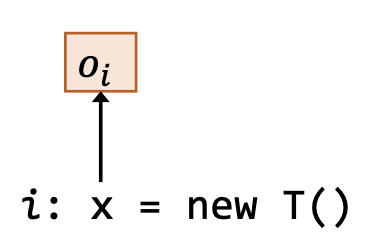 |
| 赋值 | x = y |
$o_i\in pt(y)$ $\overline{o_i \in pt(x)}$ |
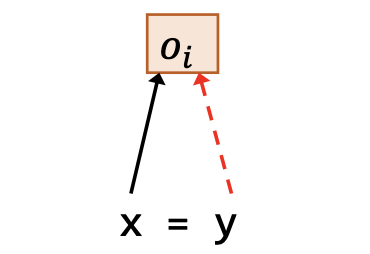 |
| 存储 | x.f = y |
$\underline{o_i \in pt(x), o_j\in pt(y)}$ $o_j \in pt(o_i.f)$ |
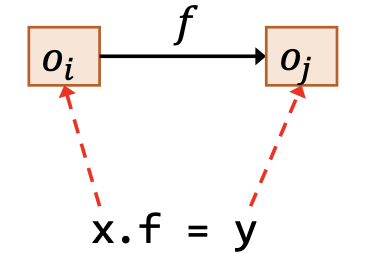 |
| 载入 | y = x.f |
$\underline{o_i\in pt(x), o_j\in pt(o_i.f)}$ $o_j\in pt(y)$ |
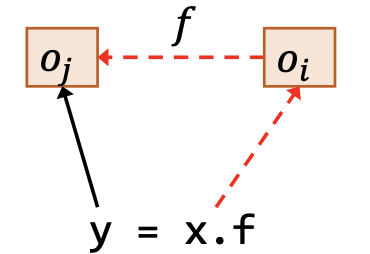 |
如何理解指针流图(Pointer Flow Graph)?
一个程序的指针流图(Pointer Flow Graph)指的是表示对象如何在程序中的指针之间流动的有向图。
-
PFG中的一个节点$n$代表了一个变量或者某个对象的一个字段,即
\[n\in Pointer \subseteq V \cup (O\times F)\]PFG中的所有节点就是程序中的所有指针。
-
PFG中的一条边$x \to y \in Pointer \times Pointer$表示指针$x$指向的对象可能会流到指针$y$的指向集合中(即也可能被$y$指向)。
其中,$V$表示程序中所有变量的集合,$O$表示所有对象的集合,$F$表示所有字段的集合。
对于各种类型的语句,这样添加PFG边。
指针分析算法(Pointer Analysis Algorithms)的基本过程是什么?
以下两个步骤相互依赖,动态更新:
- 构建指针流图 PFG
- 在 PFG 上传递指向信息

如何理解方法调用(Method Call)中指针分析的规则?
| 类型 | 语句 | 规则 | PFG边 |
|---|---|---|---|
| 调用 | l: r = x.k(a1, ..., an) |
$o_i\in pt(x), m=Dispatch(o_i, k)$ $o_u\in pt(a_j), 1\le j\le n$ $o_v\in pt(m_{ret})$ $\overline{o_i\in pt(m_{this})}$ $o_u\in pt(m_{p_j}), 1\le j\le n$ $o_v\in pt(r)$ |
$a_1\to m_{p_1}$ … … $a_n\to m_{p_n}$ $m_{ret}\to r$ |
怎样理解过程间的指针分析算法(Inter-procedural Pointer Analysis Algorithm)?
过程间的指针分析是和调用图的构建一起进行的,也就是说,指针分析和调用图构建之间就像指针分析和指针流图构建之间一样,是相互依赖的。调用图向我们描述了一个“可达的世界”:
- 入口方法(比如说 main 方法)是一开始就可达的;
- 其他的可达方法是在分析的过程中不断发现的;
- 只有可达的方法和语句才会被分析。
称调用图中,入口方法(Entry Methods)以及从入口方法可达的其他结点为可达方法(Reachable Methods)。所有的可达方法构成了一个可达调用子图(Reachable Sub-Call-Graph)。
即时调用图构建(On-the-fly Call Graph Construction)的含义是什么?
称一边使用调用图,一边构建调用图的方式为即时调用图构建(On-the-fly Call Graph Construction)。
基于指针分析来构建调用图的过程中,反过来又会促进指针分析的过程,因为调用边和返回边也是会传递指向关系的,从而两者是相互依赖的,我们称这种调用图的构建方式为即时调用图构建(On-the-fly Call Graph Construction)。
上下文敏感(Context Sensitivity, C.S.)是什么?
称一个静态分析是上下文敏感的(Context-Sensitive, C.S.),如果它区分一个方法的不同调用语境(Calling Context);称一个静态分析是上下文不敏感的(Context-Insensitive, C.I.),如果它将一个方法所有的调用语境汇合到一起分析。在上下文敏感的分析中,对于每一个调用的上下文都会单独分析,因此,一个方法可能在不同的上下文中被分析很多次。
上下文敏感堆(C.S. Heap)是什么?
- 抽象的对象也应当用上下文来修饰(称为堆上下文),最普遍的选择是继承该对象分配点所在方法的上下文。
- 上下文敏感的堆抽象在分配点抽象的基础上提供了一个粒度更精确的堆模型。
- 称区分堆上下文(Heap Context)的分配点抽象为上下文敏感的分配点抽象(Context-sensitive Allocation-site Abstraction)。
为什么 C.S. 和 C.S. Heap 能够提高分析精度?
C.S.
- 在动态执行的过程中,每一个方法可能在不同的调用语境中被调用多次。
- 在不同的调用语境下面,方法中的变量可能会指向不同的对象。
- 在上下文不敏感的指针分析中,不同的上下文被混合在了一起,并传递给程序的其他部分(通过返回值或者副作用),这就导致了虚假的数据流。
C.S. Heap
- 在动态执行的过程中,一个分配点可以在不同的调用语境下创建多个对象;
- 不同的对象(有相同的分配点分配)可能会携带不同的数据流被操作,比如说在它们的字段中存储不同的值。
- 在指针分析中,不带堆上下文分析这样的代码可能会由于合并不同上下文中的数据流到一个抽象对象中而丢失精度。
- 相比之下,通过堆上下文来区分同一个分配点的不同对象能够获得不少的精度。
上下文敏感的指针分析有哪些规则?
| 类型 | 语句 | 规则(在上下文 $c$ 下) | 图示 |
|---|---|---|---|
| 创建 | i: x = new T() |
$\overline{c:o_i \in pt(c:x)}$ | 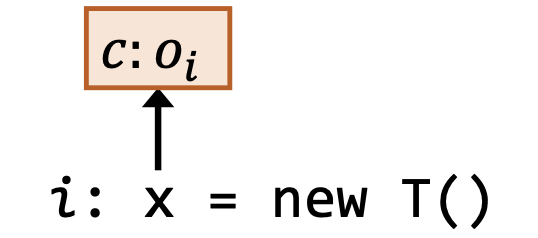 |
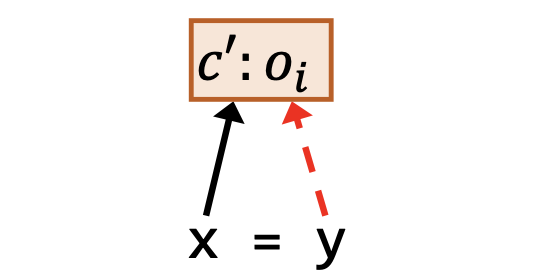
| 赋值 | x = y |
$\underline{c’:o_i\in pt(c:y)}$ $c’:o_i \in pt(c:x)$ |
 |
| 存储 | x.f = y |
$\underline{c’:o_i\in pt(c:x), c’‘:o_j\in pt(c:y)}$ $c’‘:o_j\in pt(c’:o_i.f)$ |
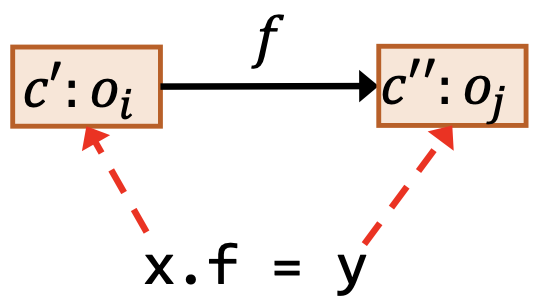 |
| 载入 | y = x.f |
$\underline{c’:o_i\in pt(c:x), c’‘:o_j\in pt(c’:o_i.f)}$ $c’‘:o_j\in pt(c:y)$ |
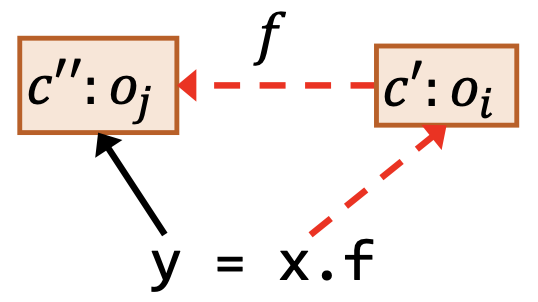 |
调用语句还要为被调用者生成新的上下文。
| 类型 | 语句 | 规则(在上下文 $c$ 下) |
|---|---|---|
| 调用 | l: r = x.k(a1, ..., an) |
$c’:o_i\in pt(c:x)$ $m = Dispatch(o_i, k), c^t = Select(c, l, c’:o_i)$ $c’‘:o_u\in pt(c:a_j), 1\le j\le n$ $\underline{c’’‘:o_v\in pt(c^t:m_{ret})}$ $c’:o_i\in pt(c^t:m_{this})$ $c’‘:o_u\in pt(c^t:m_{p_j}), 1\le j\le n$ $c’’‘:o_v\in pt(c:r)$ |
$Select(c,l,c′:o_i)$根据在调用点$l$处可获得的信息为目标方法$m$选择一个上下文,即目标上下文的生成函数。它是从调用者上下文(Caller Context)到被调用者上下文(Callee Context)的映射。
- $Select$的输入是调用点$l$、调用点处的上下文$c$、接收对象$c′:o_i$;
- $Select$的输出是目标方法的的上下文$c^t$。
$Select$的实现方式取决于上下文敏感性变体。
如何理解上下文敏感的指针分析算法(Algorithm for Context-sensitive Pointer Analysis)?
| 类型 | 语句 | 规则(在上下文 $c$ 下) | PFG边 |
|---|---|---|---|
| 创建 | i: x = new T() |
$\overline{c:o_i \in pt(c:x)}$ | $N/A$ |
| 赋值 | x = y |
$\underline{c’:o_i\in pt(c:y)}$ $c’:o_i \in pt(c:x)$ |
$c:y \to c:x$ |
| 存储 | x.f = y |
$\underline{c’:o_i\in pt(c:x), c’‘:o_j\in pt(c:y)}$ $c’‘:o_j\in pt(c’:o_i.f)$ |
$c:y \to c’:o_i.f$ |
| 载入 | y = x.f |
$\underline{c’:o_i\in pt(c:x), c’‘:o_j\in pt(c’:o_i.f)}$ $c’‘:o_j\in pt(c:y)$ |
$c’:o_i.f\to c:y$ |
| 调用 | l: r =x.k(a1, ..., an) |
$c’:o_i\in pt(c:x)$ $m = Dispatch(o_i, k), c^t = Select(c, l, c’:o_i)$ $c’‘:o_u\in pt(c:a_j), 1\le j\le n$ $\underline{c’’‘:o_v\in pt(c^t:m_{ret})}$ $c’:o_i\in pt(c^t:m_{this})$ $c’‘:o_u\in pt(c^t:m_{p_j}), 1\le j\le n$ $c’’‘:o_v\in pt(c:r)$ |
$c:a_1\to c^t:m_{p_1}$ $… …$ $c:a_n \to c^t:m_{p_n}$ $c^t:m_{ret}\to c:r$ |
上下文敏感的指针分析算法只是在上下文不敏感算法的基础上增加了上下文敏感的内容,更具体的,只是在指针和对象之前加上了上下文的修饰,并在调用语句的处理当中增加了新上下文的生成已,整体的思路和框架没有发生任何变化。此外,设置入口方法的上下文为空,因为一般情况下程序的入口方法只会被操作系统调用一次,因而不需要用上下文加以区分。
常见的上下文敏感性变体(Context Sensitivity Variants)有哪些?
- 调用点敏感
- 对象敏感
- 类型敏感
通常,在面向对象语言的实践过程中:
- 精度方面:对象敏感 > 类型敏感 > 调用点敏感
- 效率方面:类型敏感 > 对象敏感 > 调用点敏感
常见的几种上下文变体之间的差别和联系是什么?
定义一个指针分析的上下文敏感性(Context Sensitivity)为一个上下文生成子(Context Generator),记为 $Select(c,l,c’:o_i)$,描述了实例方法调用的时候用怎样的上下文去修饰目标方法。
Select 函数的输入是调用点处的上下文$c$,调用点$l$,以及调用方法的带有堆上下文的接收对象$c’:o_i$。 Select 函数的输出是用于修饰目标方法上下文。 定义上下文不敏感(Context InSensitivity):
\[Select(\_,\_,\_)=[]\]调用点敏感
-
定义调用点敏感(Call-Site Sensitivity):
\[c=[l',\cdots,l'']\Rightarrow Select(c,l,\_)=[l',\dots,l'',l]\]调用点敏感也称为调用串敏感(Call-String Sensitivity)。
-
定义k-调用点敏感(k-Call-Site Sensitivity):
\[c=[l_1,l_2,\dots,l_k]\Rightarrow Select(c,l,\_)=[l_2,\dots,l_k,l]\]此时,每个上下文都由调用串的最后$k$个调用点组成。 k-调用点敏感也称为k-控制流分析(k-CFA, Control Flow Analysis)。 具体地:
-
1-调用点敏感
\[Select(\_,l,\_)=[l]\] -
2-调用点敏感
\[c=[l',l'']⟹Select(c,l,\_)=[l'',l]\]
-
对象敏感
-
定义对象敏感(Object Sensitivity):
\[c'=[o_j,\dots ,o_k] \Rightarrow Select(\_,\_,c':o_i)=[o_j,\dots,o_k,o_i]\]对象敏感也称作分配点敏感(Allocation-Site Sensitivity)。
-
定义k-对象敏感(k-Object Sensitivity):
\[c'=[o_1, \dots, o_k]\Rightarrow Select(\_,\_,c':o_i)=[o_2, \dots, o_k, o_i]\]-
特别地,1-对象敏感:
\[Select(\_,\_,c':o_i)=[o_i]\]
-
类型敏感
-
定义类型敏感(Type Sensitivity):
\[c'=[t',\dots,t'']\Rightarrow Select(\_,\_,c':o_i)=[t',\dots,t'',InType(o_i)]\]其中,$InType(o_i)$表示$o_i$是在哪个类中被创建的。
-
定义k-类型敏感(k-Type Sensitivity):
\[c'=[t_1,\dots,t_k]\Rightarrow Select(\_,\_,c':o_i)=[t_2,\dots,t_k,InType(o_i)]\]其中,$InType(o_i)$表示$o_i$是在哪个类中被创建的。
静态分析与安全
信息流安全(Information Flow Security)的概念是什么?
信息流安全(Information Flow Security)是指通过追踪信息是如何在程序中流动的方式,来确保程序安全地处理了它所获得的信息。
如何理解机密性(Confidentiality)与完整性(Integrity)?
机密性(Confidentiality)指的是阻止机密的信息泄漏,完整性(Integrity)指的是阻止不信任的信息污染受信任的关键信息。 可以理解为读保护、写保护。
什么是显式流(Explicit)和隐蔽信道(Covert Channels)?
- 信息可以通过直接拷贝的方式进行流动,这样的信息流称为显式流(Explicit Flow)。
- 信息可以通过影响控制流的方式向外传递,这样的信息流称为隐式流(Implicit Flow)。例如以下代码,没有直接拷贝,却可以通过影响控制流的方式传递信息。
secret = getSectre(); if (secret < 0) publik = 1; else publik = 0; - 称在计算系统中指示信息的机制为信道(Channels)。如果这个指示信息的机制的本意并不是信息传递,这样的信道称为隐蔽信道(Covert/Hidden Channels)。
如何使用污点分析(Taint Analysis)来检测不想要的信息流?
- 污点分析:污点分析(Taint Analysis)将程序中的数据分为两类:
- 关心的敏感数据,我们会给这些数据加标签,加上标签后叫做 污点数据(Tainted Data) ;
- 其他数据,叫做 无污点数据(Untainted Data) 。
污点分析追踪污点数据是如何在程序中流动的,并且观察它们是否流动到了一些我们关心的敏感的地方。其中,污点数据产生的地方称为源头(Source),我们不希望污点数据流向的敏感地带称为水槽(Sink)。
- 分析机密性
- 源头:保密数据源
- 水槽:泄漏点
- 分析完整性
- 源头:不信任数据源
- 水槽:关键计算
基于 Datalog 的程序分析
Datalog 语言的基本语法和语义是什么?
Datalog 的语法语义由两部分组成,数据(Data)和逻辑(Logic),这种语言没有副作用,没有控制流,没有函数,也不是图灵完备的语言。在 Datalog 中,用谓词表示数据,用规则表示逻辑。
原子
在 Datalog 语言中,称返回值为 True 或者 False 的表达式(Expression)为原子(Atom)。
在 Datalog 语言中,称形如$P(x_1, x_2, \dots, x_n)$的表达式为关系型原子(Relational Atoms),其中$P$称为谓词(Predicates)或关系(Relation), $x_i(1\leq i\leq n)$ 称为实参(Arguments)或者项(Terms)。
记$x_1 \in X_1, x_2 \in X_2, \dots, x_n \in X_n$,则有
\[P\subseteq X_1 \times X_2 \times \dots \times X_n\]且定义
\[P(x_1, x_2, \dots, x_n) = True \Leftrightarrow (x_1, x_2, \dots, x_m) \in P\]此时,称为$(x1,x2,…,xn)$为$P$中的一个事实(Fact)。
在Datalog语言中,称可判定真假的代数表达式为代数型原子(Arithmetic Atoms)。
规则
在Datalog语言中,称形如$H\leftarrow B_1,B_2,\dots,B_n.$的语句为规则(Rules),其中:
- $H$称为头部(Header),是规则的结果(Consequent),其形式上是一个原子。
- $B_1,B_2,\dots,B_n$称为主体(Body),是规则的前提(Antecedent),其中的$B_i$是一个原子或者原子的否定,称为子目标(Subgoal)。
规则的含义是如果主体为真,则头部为真。这里 , 表示合取关系,即逻辑与,也就是说主体$B_1,B_2,\dots,B_n$为真当且仅当所有的子目标$B_i(1\leq i\leq n)$都为真。
EDB和IDB谓词
- 在 Datalog 语言中,称先验定义的谓词为外延数据库(Extensional Database,EDB),其中的关系是不可修改的,可视为输入关系。
- 在 Datalog 语言中,称由规则建立的谓词为内涵数据库(Intensional Database,IDB),其中的关系是由规则推导出来的,可视为输出关系。
在 Datalog 本身的规约中,对于规则语句,其头部只能是 IDB ,但主体部分的原子既可以是 EDB ,也可以是 IDB 。换句话说, Datalog 支持递归的规则(Recursive Rules)。
析取
在Datalog中,有两种方式来表达析取逻辑:
- 书写多个具有相同头部的规则,其含义是任意一个规则都能够生成那个头部原子谓词中的事实。
SportFan(person) <- Hobby(person, "jogging"). SportFan(person) <- Hobby(person, "swimming"). - 使用逻辑或操作符
;。SportsFan(person) <- Hobby(person, "jogging"); Hobby(person, "swimming").
否定
在Datalog的规则中,一个子目标也可以是某个原子的否定,写作!B(...),表示B(...)的相反意思,即!B(...)为真当且仅当B(...)为假。
如何用 Datalog 来实现指针分析?
- EDB 其实就是我们能够从程序句法上直接提取的指针相关的信息;
- IDB 就是我们需要的指针分析的结果;
- 规则可以直接用指针分析的规则。
建模
-
EDB |类型|语句|EDB| |:-:|:-:|:-:| |创建|
i: x = new T()|New(x: V, o: O)| |赋值|x = y|Assign(x: V, y: V)| |存储|x.f = y|Store(x: V, f: F, y: V)| |载入|y = x.f|Load(y: V, x: V, f: F)| -
IDB 指针分析的结果 IDB 的形式为
VarPointsTo(v: V, o: O)和FieldPointsTo(oi: O, f: F, oj: O)。 例如:- $VarPointsTo(x, o_i)$ 表示 $o_i \in pt(x)$ ,
- $FieldsPointsTo(o_i, f, o_j)$ 表示 $o_j \in pt(o_i.f)$ 。
规则
| 类型 | 语句 | 规则 | Datalog |
|---|---|---|---|
| 创建 | i: x = new T() |
$\overline{o_i \in pt(x)}$ | VarPointsTo(x, o) <-New(x, o). |
| 赋值 | x = y |
$o_i\in pt(y)$ $\overline{o_i \in pt(x)}$ |
VarPointsTo(x, o) <-Assign(x, y),VarPointsTo(y, o). |
| 存储 | x.f = y |
$o_i \in pt(x)$ $\underline{o_j\in pt(y)}$ $o_j \in pt(o_i.f)$ |
FieldPointsTo(oi, f, oj) <-Store(x, f, y),VarPointsTo(x, oi),VarPointsTo(y, oj). |
| 载入 | y = x.f |
$o_i\in pt(x)$ $\underline{o_j\in pt(o_i.f)}$ $o_j\in pt(y)$ |
VarPointsTo(y, oj) <-Load(y, x, f),VarPointsTo(x, oi),FieldPointsTo(oi, f, oj). |
处理方法调用
- 方法派发与
this变量绑定 - 将形参绑定到实参
- 将返回值传递给接收变量
如何用 Datalog 来实现污点分析?
基于指针分析,下面只描述指针分析以外的部分。
- EDB 谓词:
Source(m: M)污点源方法;Sink(m: M, i: N*)槽方法;Taint(l: S, t: T)联系调用点和从调用点出来的污点数据。
- IDB 谓词
TaintFlow(sr: S, sn: S, i: N*)检测到的污点流。TaintFlow(sr, sn, i)表示从sr流出的污点数据可能会流到槽调用sn的第i个参数中。
- 处理源头(生成污点数据)
| 类型 | 语句 | 规则 | Datalog |
|---|---|---|---|
| 调用 | l: r = x.k(a1, ..., an) |
$l\to m\in CG$ $\underline{m\in Sources}$ $t_l \in pt(r)$ |
VarPointsTo(r, t) <-CallGraph(l, m),Source(m),CallReturn(l, r),Taint(l, t). |
- 处理槽(生成污点流信息)
| 类型 | 语句 | 规则 | Datalog |
|---|---|---|---|
| 调用 | l: r = x.k(a1, ..., an) |
$l\to m\in CG$ $(m, i) \in Sinks$ $t_j\in pt(a_i)$ $\overline{(j, l, i) \in TaintFlows}$ |
TaintFlow(j, l, i) <-CallGraph(l, m),Sink(m, i),Argument(l, i, ai),VarPointsTo(ai, t)Taint(j, t). |
CFL 可达与 IFDS
- 称在CFG中,当实际运行时,某个特定的输入下,控制流会经过的路径为可行路径(Feasible Path);
- 相反,如果任何输入下,控制流都不经过某条路径,那么这条路径就称为不可行路径(Infeasible Path)。
- 称返回边和调用边相匹配的路径为可实现路径(Realizable Path);
- 不匹配则称为不可实现路径(Unrealizable Path)。
一个可实现的路径不一定会被执行,但是一个不可实现的路径一定不会被执行。
什么是 CFL 可达(CFL-Reachability)?
为一张有向图中的每条边打上标签,称结点B从结点A是CFL可达(CFL Reachable)的,如果存在从A到B的路径,该路径上每条边的标签组成了某个特定的上下文无关语言(Context-free Language, CFL)的合法字符串。
其中,这个上下文无关语言是根据需求相应定义的。通过CFL可以定义出部分平衡括号问题(Partially Balanced-Parenthesis Problem):
- 每个右括号 $)_i$ 都应当有一个左括号 $(_i$ 与之平衡,但反之不亦然;
- 对于每个调用点 $i$ ,将它的调用边标记为 $(_i$ ,返回边标记为 $)_i$ ;
- 将其他所有的边标记为 $e$ 。
于是,我们会发现,一个路径是可实现的,当且仅当这个路径上的标记所形成的字符串在语言 $L(realizable)$ 中,其中:
\[\begin{aligned} realizable &\to matched\ realizable\\ &\to (_i\ realizable\\ &\to \varepsilon\\ matched &\to (_i\ matched\ )_i\\ &\to e\\ &\to \varepsilon\\ &\to matched\ matched \end{aligned}\]IFDS(Interprocedural Finite Distributive Subset Problem)的基本想法是什么?
IFDS(Interprocedural Finite Distributive Subset Problem) **指的是一类过程间(Interprocedural)数据流分析的子问题,其流函数具有分配性(Distributive),定义域是有限(Finite)集。其中,流函数(Flow Functions)**由结点转移和边转移组成。
IFDS是一种通过图可达性的方式进行静态程序分析的框架,为数据流分析提供了一种可实现全路汇集(MRP)的解决方案,MRP的定义与全路汇集(MOP)类似。
MRP
定义 可实现全路汇集(Meet-Over-All-Realizable-Paths, MRP) 的解决方案(以前向分析为例,后向分析倒过来即可)通过如下步骤计算某个程序点 $(s_i, s_{i+1})$ (见定义3.4)处的数据流值,记为 $MRP[s_i]$ :
- 考虑从程序入口到 $s_i$ 处的路径 $P$ 的 流函数(Flow Function) 为 $F_P$ ,所有可实现路径的集合记为 $RPaths(ENTRY, s_i)$ ;
- 这里的流函数的作用类似于状态转移方程,只不过状态转移方程是结点转移,这里说的是边转移(结点转移可以转化成边转移,后续会有例子)。
- 一条路径的流函数是路径上边的流函数的复合。
- 使用联合(join)或者汇集(meet)操作来求这些值的最小上界或者最大下界。
形式化表示为:
\[MRP[s_i] = \bigvee_{\forall P \in RPaths(ENTRY, s_i)} F_P(OUT[ENTRY])\]此时,一般 $OUT[ENTRY] = \bot$ ,详见 4.1.1。
或
\[MRP[s_i] = \bigwedge_{\forall P \in RPaths(ENTRY, s_i)} F_P(OUT[ENTRY])\]此时,一般 $OUT[ENTRY] = \top$ ,详见 4.1.2。
基本步骤
给定一个程序 $P$ ,和一个数据流分析问题 $Q$
- 为 $P$ 建立一个 超图(Supergraph) $G^{}$ 并且根据 $Q$ 定义 $G^{}$ 中边的流函数;
- 通过将流函数转化成 代表关系(Representation Relations) 的方式,基于 $G^{*}$ 为 $P$ 建立一个 分解超图(Exploded Supergraph) $G^{\sharp}$ 。
- $Q$ 可以被当作图 $G^{\sharp}$ 上的可达性问题来解决(寻找MRP解决方案),具体地,通过在 $G^{\sharp}$ 上运行制表算法来解决。
令 $n$ 是某个程序点, 数据流因素 $d \in MRP[n_i]$ 当且仅当在 $G^{\sharp}$ 中存在一条从 $(s_{main}, 0)$ 到 $(n_i, d)$ 的可实现的路径。
超图
在IFDS中,程序用 超图(Supergraph) $G^{} = (N^{}, E^{*})$ 表示。
- $G^{*}$ 是由一组控制流图(Control Flow Graph)$G_1, G_2, …$ 组成的,每个过程 $Procedure_i$ 都有一个对应的控制流图 $G_i$。
- 每一个控制流图 $G_p$ 都有自己独特的一个起始结点(Start Node) $s_p$ 和结束结点(Exit Node) $e_p$ 。
- 在每个过程的控制流图 $G_i$ 中,用调用结点(Call Node) $Call_p$ 和 返回点结点(Return-site Node) $Ret_p$ 来表示对 $Procedure_p$ 的过程调用。
- 除了每个过程内部的控制流边以外,对于每个过程调用, $G^{*}$ 还有另外3种边:
- 一条过程内的,从调用者的 $Call_p$ 到 $Ret_p$ 的 调用返回边(call-to-return-site edge) ,
- 一条过程间的,从调用者 $Call_p$ 到被调用者的 $s_p$ 的 调用起始边(call-to-start-edge) ,
- 一条过程间的,从被调用者的 $e_p$ 到调用者的 $Ret_p$ 的 结束返回边(exit-to-return-edge) 。
这里的超图和过程间控制流图很像,只是它将调用点拆分成了调用结点与返回点结点两个部分而已。
流函数
以下面这个问题为例。 定义 可能未初始化变量(Possibly-uninitialized Variables) 问题:对于 $N^{*}$(超图的结点集合) 中的每个结点 $n$ ,求在执行 $n$ 之前有可能未初始化的变量集合。
定义lambda表达式形如 $\lambda e_{param}. e_{body}$ ,其中 $e_{param}$ 是形参表, $e_{body}$ 是函数体。
采用 $(\lambda e_{param}. e_{body})(e_{arg})$ 的形式来调用这个匿名函数,其中 $e_{arg}$ 是实参表,如果只有一个元素,实参表的括号可以省略。
分解超图
将流函数转换成代表关系,把超图变成分解超图。
对于流函数 $f$ ,其 代表关系(Representation Relation) 是一个二元关系 $R_{f} \subseteq (D \cup {0}) \times (D \cup {0})$ ,其定义如下:
\[R_f = \{(0, 0)\} \cup \{(0, y)| y \in f(\emptyset)\}\cup\{(x, y)|y \notin f(\emptyset) \wedge y\in f(\{x\})\}\]用二部图 $G$ 来表示上面的二元关系,则 $(d_1, d_2) \in R_f \Leftrightarrow d_1\to d_2 \in G$ 。
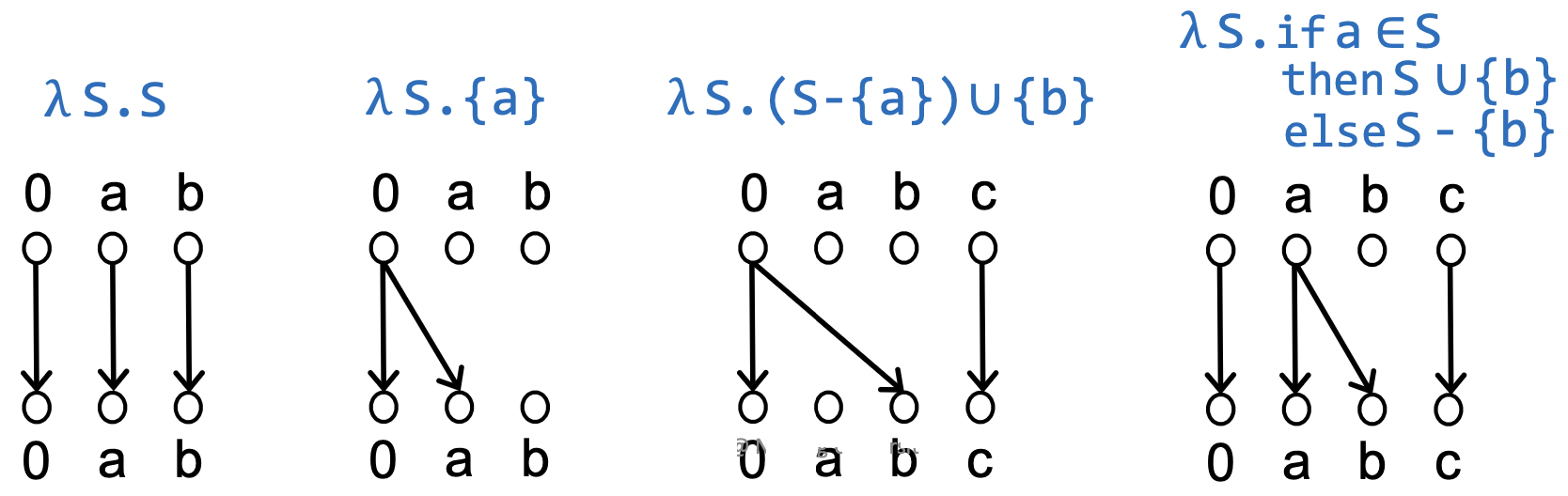
用有序对 $(n_i, d)$ 表示程序点 $(n_i, n_{i+1})$ 处的数据流因素 $d$ ,用 $(n_i, 0)$ 表示该程序点处特殊的数据流因素 $0$ 。 定义 分解超图(Exploded Supergraph) 形如 $G^{\sharp} = (V^{\sharp}, E^{\sharp})$ ,其中:
-
$V^{\sharp} = {(n_i, d) n_i\ is\ a\ program\ point\ and\ d\ is \ a\ dataflow\ factor}$ 。 - $(n_i, d_1) \to (n_{i + 1}, d_2) \in E^{\sharp} \Leftrightarrow (d_1, d_2) \in R_{f_i}$ ,其中, $f_i$ 是 $i$ 处的流函数。
称分解超图 $G^{\sharp}$ 中形如 $(n_i, 0) \to (n_{i+1}, 0)$ 这样的边为 粘边(Glue Edge) 。IFDS 中分解超图上的粘边是为了表达出流函数的复合运算。
制表算法
制表算法(Tabulation Algorithm) 的功能是给定分解超图,求其中的所有可实现路径。
怎样的问题可以用 IFDS 来解决?
回顾:分配性是指$f(x\vee y)=f(x)\vee f(y)$,$f(x\wedge y)=f(x)\wedge f(y)$。
分配性是 IFDS 的关键,定义可达性问题、活跃变量问题、空闲表达式问题是可分配的(所有的 $gen/kill$ 问题都是可分配的),可以用 IFDS 解决。但是像常量传播、指针分析这类不可分配的问题,就没有办法用标准的 IFDS 方法解决。在 IFDS 中,每个流函数一次只能处理一个数据流因素——即只能计算 $F(x)$ 或者 $F(y)$ ,不能计算 $F(x\wedge y)$ 。因为每个代表关系只能说明“如果$x$存在,那么 …”,“如果$y$存在,那么…”但是并不能表达“如果$x$和$y$都存在,那么…”这样的逻辑。
完全性与近似完全性
近似完全性(Soundiness)的动机和概念是什么?
-
动机:对于静态分析来说, 难分析的特性(Hard-to-analyze Features)或者简称难的特性(Hard Feature)是指:对这些特性进行激进的保守处理(即完全的过近似)可能会使分析过于不精确而无法扩展(scale),从而使分析变得无用。
-
概念:一个近似完全的(soundy)静态分析通常意味着这个分析大多数时候是完全的,并且对于进行了不完全处理的难的或者特定的语言特性有着良好的标注和说明。 称一个近似完全的静态分析具有近似完全性(Soundiness)。
为什么 Java 反射(Reflection)和原生代码是难分析的?
Java 反射
反射(Reflection)是Java编程语言中的一个特性。它允许正在执行的Java程序检查或“自省”自身,并操纵程序的内部属性。
- Java反射除了反射函数本身之外,还会产生别的新的过程间的控制流边(调用边、返回边),而这些边会大大影响全程序分析的结果。
- Java反射会修改程序的内部属性,从而产生一些副作用,这也是不能忽略的。特别是在做一些验证(Verification)或者优化(Optimization)的时候,如果忽略了反射机制的副作用,就会导致不安全或者错误的结果。
原生代码
Java原生接口(Java Native Interface, JNI)是JVM的一个功能模块,允许Java代码和原生代码(C/C++)之间的交互。 Java的分析器无法直接分析C/C++的接口。所以这是一个难问题。